
The Kubernetes Eras Tour: How Zynga Games Streamlined K8s Upgrades
Authors: Daniel Lakin, Justin Schwartz, Krunal Soni, Molly Sheets, Pratibha Gupta

Intro to the Eras
Zynga is an enthusiastic user of Kubernetes, with dozens of games and critical applications running on over 20 clusters, both multi-tenant and single tenant, across the company today. Zynga’s Central Tech Kubernetes team supports 170 backend engineers and engineering managers as its customers. This team manages and maintains Amazon Web Services Elastic Kubernetes Service (Amazon EKS) clusters for multiple teams at Zynga, providing common services like networking, logging, and autoscaling, while still giving game and other engineering teams the autonomy they desire. Regularly upgrading clusters is a key part of those services.
However, adopting and seamlessly upgrading K8s clusters at Zynga has been a journey full of growing pains.The Zynga Kubernetes team started with just a handful of engineers, evolving from a mini-team within a team to an independent one. In the early days upgrades could be handled entirely by the team lead, since the lift involved with upgrades back then was relatively small, both in terms of the number of clusters and their size. Within a year of the team’s creation, that began to change, as more and more teams migrated applications and games away from EC2 onto K8s. The number of workloads within them exploded, with Zynga’s central multi-tenant cluster in particular growing to hundreds of nodes. As the mission grew, the team was forced to grow along with it, learning lessons and maturing its practices for Kubernetes upgrades.
What’s In An Upgrade? (Kubernetes Version)
The open-source Kubernetes project regularly releases updates, averaging about three new versions a year. AWS and other cloud providers closely track the upstream release cycle, providing managed versions of each new release shortly after it is generally available. Each release is only supported by AWS for a specified time period, and if users do not upgrade, they risk losing support and security updates, as well as missing out on new features. They might even be auto-upgraded by AWS in some instances, leading to unanticipated issues.
At a high level, a Kubernetes upgrade involves two steps: upgrading the control plane and upgrading the data plane. The control plane consists of the Kubernetes API server, etcd data storage, and other key components like the Scheduler and Cloud Controller Manager. In EKS, the control plane is managed by AWS, and upgrading it is as simple as clicking a button. Upgrading the data plane is where it can get complicated.
The data plane consists of all other parts of the cluster: worker nodes and the Kubelet running on them, pods and other Kubernetes constructs, and all system addons that provide key cluster services. When it’s time to upgrade, the Zynga Kubernetes team has to handle each of the following:
Identify all API deprecations or removals coming in the next release or releases and audit all EKS clusters to check for objects affected
Make any updates required for the apps and internal tooling managed by the Zynga Kubernetes team
Work with customers to make sure their apps are forward compatible
Schedule upgrades to allow time for dev and staging environments to go first and “soak” before upgrading production
The (Scary) Fearless Era
The first few cycles of Kubernetes upgrades at Zynga were necessarily ad hoc, as the team tried to both build and fly the plane at the same time. The below graphic captures the more irregular upgrade cadence of those days.

As can be seen from the timeline, early Kubernetes upgrades were done irregularly, with some coming close together and other times almost a whole year passing between versions. The team actually missed the end-of-support date when upgrading from version 1.13 to 1.15, spending almost a month on an unsupported version. In the first years of Kubernetes at Zynga, the team struggled with several key issues:
A limited visibility into cluster operations and metrics, and tools for verifying functionality during and after an upgrade
The team had a limited visibility when it came to API deprecations and removals, and could not be certain whether apps running on Zynga’s EKS clusters were using old API versions
The number of nodes in Zynga’s clusters quickly blew past the point where they could be manually rotated during upgrades
Lack of advance planning - for the first three upgrade cycles, the team did not prepare technical documentation
Communication - the team had to mature and systematize its communications to give cluster tenants plenty of advance notice to update their applications, and work to handle edge cases
These struggles occasionally manifested in a choppy upgrade process. For example, some lingering uses of deprecated APIs after an upgrade caught the team by surprise and resulted in a few application outages.
The (Better) Reputation Era
Throughout its existence, the Zynga Kubernetes team has worked hard to mature its practices and provide a more seamless upgrade experience. These changes have been comprehensive, and start with a more regular cadence. As the graphic below shows, starting in 2022 the team has maintained a consistent rhythm, starting with researching and writing a detailed tech spec for the upgrade and finishing the work well before end of support in AWS.
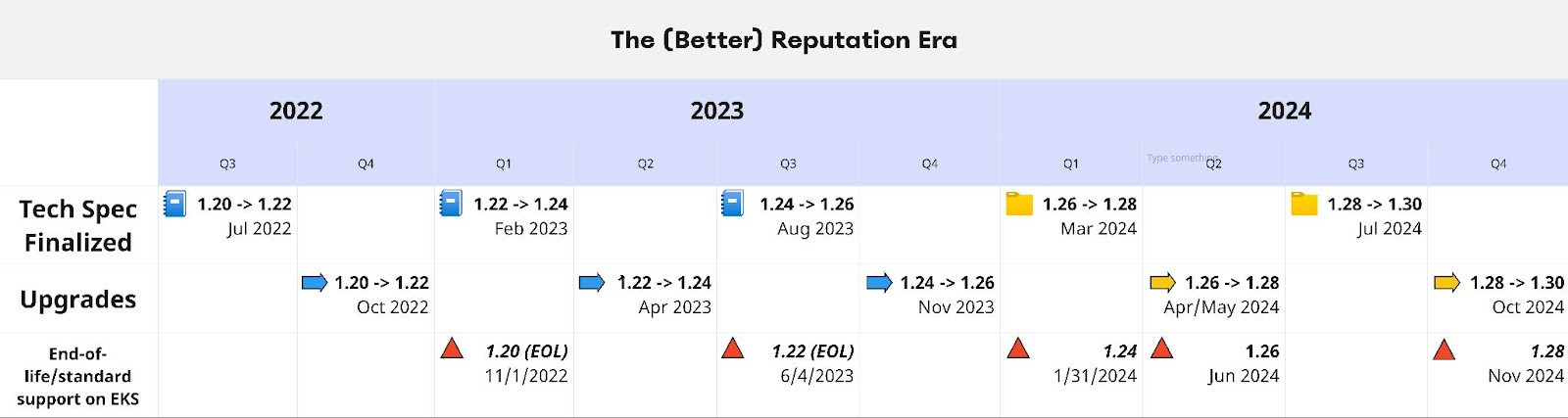
The team has also made strides in four key areas of the upgrade process:
API Deprecation Detection
Starting in 2020, the team has expanded its ability to detect usage of deprecated and removed APIs in EKS clusters. For several cycles, the team used the Pluto tool to manually generate reports of API usage that needed to be addressed, which were then shared with cluster tenants well ahead of an upgrade. While this was much better than the previous state, Pluto has some real weaknesses as a tool, so more recently, the team created a Splunk dashboard that uses data available in each cluster’s Kubernetes Audit Log to detect all uses of deprecated or removed APIs. This makes up-to-the-minute data on API usage available to the Zynga Kubernetes team and all cluster tenants, vastly increasing confidence in future Kubernetes upgrades.
Node Rotation Automation
As the size and scope of Kubernetes at Zynga grew, it quickly became impractical to handle node rotation during an upgrade manually. To get around that, the team developed tools to automate the work, iterating over the years to decrease the manual burden. The first improvement came in the form of a command line node termination utility that could accept arbitrary numbers of nodes, allowing the cordoning, draining, and replacement of multiple nodes at a time. However, this solution was still manually demanding and error-prone. Starting in 2022, the Kubernetes team created a fully automated command line tool that could handle scaling ahead of an upgrade, rotate nodes in parallel as configured, and still allow manual handling of edge cases. These improvements took node rotation time for our largest cluster down from eight hours to less than three.
Communication With Customers
One of the most important changes the team has made in maturing its Kubernetes upgrade process has been in its communications with cluster tenants. The Zynga Kubernetes team now sends emails detailing the upgrade process and any required changes to all customers early and often, and meets individually with specific teams to answer their questions and provide guidance. This allows all stakeholders to surface any issues early in the process, and gives the Kubernetes team a long runway to address any concerns.
The Era of Confidence
The last several Kubernetes upgrade cycles have gone incredibly smoothly, even with potentially disruptive changes like the removal of Dockershim in version 1.24, and the removal of PodSecurityPolicy in version 1.25. The Zynga Kubernetes team has hit its stride, establishing a regular upgrade cadence, building customer confidence, and completing upgrades with zero outages. The best possible testament to this came in a recent cycle, when a customer told us they didn’t notice anything even as all the nodes in their cluster were rotated and significant API changes were made. That kind of feedback is exactly what the team wants to hear, now as well as moving forward.
https://substack.com/@zyngaengineering/note/p-140984034?r=4yffgo